Building the gender classifier I've written about here got me interested in ambiguous names - those that are shared by people of both genders.
I realised I could use the list of male and female charity trustee names I'd gathered to look into this in a bit more detail. Bearing in mind the limitations and bias of the source dataset, I think it can generate some insight.
This blogpost was written as a juypter notebook, so it can be run to recreate the research. You can find the notebook code on github.
We start by importing the libraries we need - two built-in python libraries
(csv and collections), pandas for analysing the data and matplotlib
for making charts.
%matplotlib inline
import csv
from collections import Counter
import pandas as pd
To start, we go through all the names in our source data, and use the names with titles to find first names of males and females. To do this I've just taken the first word from the string, excluding the title, providing it's more than one character. This is fairly crude, and will be wrong in some cases (eg someone who uses two first names). But it should be good enough for our purposes.
names = {
"female": [],
"male": []
}
with open("extract_trustee.csv") as a:
reader = csv.reader(a)
for row in reader:
# ignore rows that aren't two records long
if len(row) != 2:
continue
name = row[1].lower().split(" ") # split the name by spaces
# if there's only one field then ignore the name
if len(name) <= 1:
continue
# if the second name string (usually surname) is less that 2 characters ignore the row
if len(name[1]) <= 2:
continue
# if there are non-alpha characters (numbers, symbols) then ignore the row
if not name[1].isalpha():
continue
name[1] = name[1].title() # get the first name (assuming name[0] is a title)
# if the first word is one of these titles it's a female name
if name[0] in ["miss", "mrs", "ms", "dame"]:
names["female"].append(name[1])
# if the first word is one of these titles it's a male name
elif name[0] in ["mr", "sir"]:
names["male"].append(name[1])
Lets check the female and male names to check we're on the right track.
print(names["female"][0:10])
print(names["male"][0:10])
['Felicity', 'Tessa', 'Elizabeth', 'Julie', 'Rosemary', 'Catherine', 'Eileen', 'Christa', 'Roberta', 'Beverley']
['Oliver', 'Kenneth', 'Neil', 'Keith', 'John', 'Herschel', 'Alex', 'David', 'Christopher', 'Daniel']
female = Counter(names["female"])
male = Counter(names["male"])
female_names = len(female)
male_names = len(male)
all_names = female_names + male_names
female_people = len(list(female.elements()))
male_people = len(list(male.elements()))
all_people = female_people + male_people
print("Female: {:,.0f} (from {:,.0f} people)".format(
female_names,
female_people,
))
print("Male: {:,.0f} (from {:,.0f} people)".format(
male_names,
male_people,
))
print("{:,.1f} % of names are female, {:,.1f} of people in sample".format(
(female_names / all_names) * 100,
(female_people / all_people) * 100
))
weighting = ((male_people / 0.489) - male_people) / female_people
print("Use a weighting of {:,.3f} to bring female population to 51.1% of sample".format(
weighting
))
# 100 = X + Y
# X = male
# Y = female
# Z = female weighted
# X / (X + Y) = 0.520
# X / (X + Z) = 0.489
# X = 0.489 * (X + Z)
# X / 0.489 = X + Z
# Z = (X / 0.489) - X
Female: 15,367 (from 335,237 people)
Male: 16,085 (from 363,296 people)
48.9 % of names are female, 48.0 of people in sample
Use a weighting of 1.132 to bring female population to 51.1% of sample
This gives us 15,367 female first names (from 335,000 people) and 16,085 male ones (from 363,296 people). The only issue is that the ratio is slightly off - 48.0% of our sample are female, compared to 51.1% of the 18+ population in England and Wales. So we can use a weighting of 1.132 to correct this when we use the counts.
Next we work out the count of how many times each name appears for men and women. To do this the data is put into panda dataframes.
female_df = pd.DataFrame.from_dict(female, orient='index')
female_df.columns = ["female"]
male_df = pd.DataFrame.from_dict(male, orient='index')
male_df.columns = ["male"]
We then apply our weighting to the female figures to adjust for the lower number in our sample.
female_df = (female_df * weighting).round(0)
These dataframes are merged together, joining on the name, to give us a list of first names found in the dataset alongside the number of females and males found with that name.
both = pd.concat([female_df, male_df], join='outer', axis=1).fillna(0)
both.loc[:, "total"] = both.loc[:, "female"] + both.loc[:, "male"]
both.loc[:, "female_pc"] = both.loc[:, "female"] / both.loc[:, "total"]
both.loc[:, "male_pc"] = both.loc[:, "male"] / both.loc[:, "total"]
both.sort_values("total", ascending=False, inplace=True)
We can see a list of the top 10 most common first names in the dataset (only two female names make the list - even after applying our weighting).
both[0:10]
| female | male | total | female_pc | male_pc | |
|---|---|---|---|---|---|
| David | 8.0 | 21480.0 | 21488.0 | 0.000372 | 0.999628 |
| John | 9.0 | 21155.0 | 21164.0 | 0.000425 | 0.999575 |
| Peter | 6.0 | 12421.0 | 12427.0 | 0.000483 | 0.999517 |
| Michael | 3.0 | 12021.0 | 12024.0 | 0.000250 | 0.999750 |
| Richard | 1.0 | 9702.0 | 9703.0 | 0.000103 | 0.999897 |
| Susan | 8872.0 | 3.0 | 8875.0 | 0.999662 | 0.000338 |
| Andrew | 1.0 | 8746.0 | 8747.0 | 0.000114 | 0.999886 |
| Paul | 3.0 | 8492.0 | 8495.0 | 0.000353 | 0.999647 |
| Robert | 1.0 | 7879.0 | 7880.0 | 0.000127 | 0.999873 |
| Margaret | 7866.0 | 5.0 | 7871.0 | 0.999365 | 0.000635 |
And a list of some of the least common - these names only appear once.
both[-10:]
| female | male | total | female_pc | male_pc | |
|---|---|---|---|---|---|
| Jibola | 0.0 | 1.0 | 1.0 | 0.0 | 1.0 |
| Jibi | 0.0 | 1.0 | 1.0 | 0.0 | 1.0 |
| Jiba | 0.0 | 1.0 | 1.0 | 0.0 | 1.0 |
| Jiaokun | 1.0 | 0.0 | 1.0 | 1.0 | 0.0 |
| Jiann | 0.0 | 1.0 | 1.0 | 0.0 | 1.0 |
| Jianmin | 1.0 | 0.0 | 1.0 | 1.0 | 0.0 |
| Jiale | 0.0 | 1.0 | 1.0 | 0.0 | 1.0 |
| Jia | 1.0 | 0.0 | 1.0 | 1.0 | 0.0 |
| Jhumar | 1.0 | 0.0 | 1.0 | 1.0 | 0.0 |
| Zyta | 1.0 | 0.0 | 1.0 | 1.0 | 0.0 |
Shared names
We now move on to what we were trying to do - get a list of names that are commonly shared between people of different genders. You can see from the top 10s above that it's not a perfect dataset - some names that you might assume are unambiguously male or female have some counterparts - there are 8 female Davids, and 3 male Susans.
This could be a mistake in the way the algorithm was applied, a typo in the data, or people who have an unusual name. But to look only at names we would expect to be more common, I've filtered to only show only names where more than 30 instances of both male and female people have the name. This threshold should also ensure we have a decent sample of people for each name.
shared = both[(both["male"] > 30) & (both["female"] > 30)].sort_values("female_pc", ascending=False)
print(len(shared))
shared
23
| female | male | total | female_pc | male_pc | |
|---|---|---|---|---|---|
| Jean | 3787.0 | 50.0 | 3837.0 | 0.986969 | 0.013031 |
| Pat | 1154.0 | 67.0 | 1221.0 | 0.945127 | 0.054873 |
| Kerry | 530.0 | 45.0 | 575.0 | 0.921739 | 0.078261 |
| Lyn | 337.0 | 36.0 | 373.0 | 0.903485 | 0.096515 |
| Kim | 711.0 | 80.0 | 791.0 | 0.898862 | 0.101138 |
| Jan | 802.0 | 108.0 | 910.0 | 0.881319 | 0.118681 |
| Lindsay | 347.0 | 62.0 | 409.0 | 0.848411 | 0.151589 |
| Sandy | 126.0 | 42.0 | 168.0 | 0.750000 | 0.250000 |
| Mel | 62.0 | 54.0 | 116.0 | 0.534483 | 0.465517 |
| Vivian | 87.0 | 79.0 | 166.0 | 0.524096 | 0.475904 |
| Leigh | 88.0 | 92.0 | 180.0 | 0.488889 | 0.511111 |
| Jose | 43.0 | 60.0 | 103.0 | 0.417476 | 0.582524 |
| Sam | 215.0 | 340.0 | 555.0 | 0.387387 | 0.612613 |
| Laurie | 32.0 | 71.0 | 103.0 | 0.310680 | 0.689320 |
| Alex | 177.0 | 506.0 | 683.0 | 0.259151 | 0.740849 |
| Chris | 419.0 | 1856.0 | 2275.0 | 0.184176 | 0.815824 |
| Ali | 52.0 | 268.0 | 320.0 | 0.162500 | 0.837500 |
| Lee | 92.0 | 524.0 | 616.0 | 0.149351 | 0.850649 |
| Ashley | 43.0 | 257.0 | 300.0 | 0.143333 | 0.856667 |
| Leslie | 78.0 | 729.0 | 807.0 | 0.096654 | 0.903346 |
| Francis | 51.0 | 533.0 | 584.0 | 0.087329 | 0.912671 |
| Terry | 54.0 | 973.0 | 1027.0 | 0.052580 | 0.947420 |
| Robin | 36.0 | 1438.0 | 1474.0 | 0.024423 | 0.975577 |
This identifies 23 names meeting our criteria. They range from Jean (97% female), to Robin (98% male). But the most interesting names come in the middle. The closest to a 50-50 split are Leigh (49% female), Vivian (52% female) and Mel (53% female).
shared[["female_pc", "male_pc"]].multiply(100).iloc[::-1].plot(kind="barh", stacked=True, figsize=(8, 8))
<matplotlib.axes._subplots.AxesSubplot at 0x23fe0924e80>
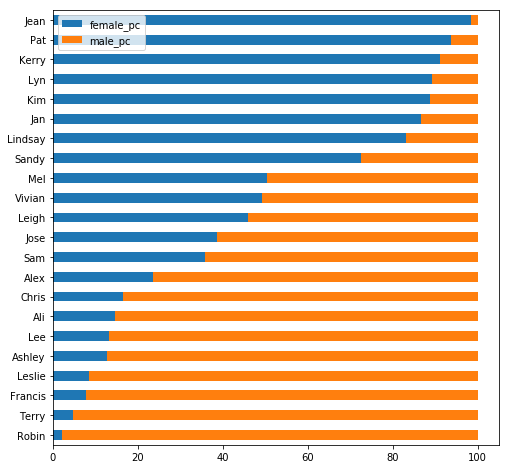
Charting the data gives us a few clusters:
- Names that are mostly female, but with some male use: Jean, Pat, Kerry, Lyn, Kim, Jan, Lindsay
- Names that are pretty close to 50-50: Mel, Vivian, Leigh, Jose, Sam
- Names that are mostly male, but with some female use: Alex, Chris, Ali, Lee, Ashley, Leslie, Terry, Robin
